
Understanding CircleCI Workspaces: How Data Flows Across Jobs
When working with CircleCI, one powerful feature that aids in managing data between jobs is the use of workspaces. However, understanding how data within workspaces flows is not immediately clear. This guide will help you grasp how data persistence in workspaces works.
Today I struggled for a few hours trying to understand why I was seeing the entire repo and the node_modules folder in my deploy job while using CircleCI workspaces. After some investigation, I found the root cause and managed to move past this issue. To save others from the hours I spent trying to figure this out, I decided to publish the blog that I wish had existed before I invested so much time into this mystery.
What Are CircleCI Workspaces?
CircleCI workspaces provide a mechanism to persist data from one job and make it available to subsequent jobs. This feature is particularly useful for sharing build artifacts, dependencies, and other important files between jobs in a workflow.
How Workspaces Handle Data
A key aspect of CircleCI workspaces is that they compound data from multiple jobs. This means that each time you persist data to the workspace, it adds to the existing workspace content rather than replacing it. This compounding behavior can lead to unexpected results if not managed carefully.
The Compounding Effect: A Step-by-Step Example
Let's illustrate how this compounding effect works with a practical example.
Step 1: Initial Job - Checkout and Install Dependencies
In the first job, we check out the repository and install dependencies. We then persist these to the workspace.
jobs:
checkout_and_install_deps:
docker:
- image: cimg/node:18.14.0
working_directory: .
steps:
- checkout
- run:
name: Install dependencies
command: npm install
- persist_to_workspace:
root: .
paths:
- .Step 2: Build Job - Attach Workspace and Build Project
In the second job, we attach the workspace, which now includes the repository and node_modules, then build the project and persist the build directory.
jobs:
build:
docker:
- image: cimg/node:18.14.0
working_directory: .
steps:
- attach_workspace:
at: .
- run:
name: Build project
command: npm run build
- persist_to_workspace:
root: .
paths:
- buildStep 3: Deploy Job - Attach Workspace and Deploy Artifacts
In the third job, we attach the workspace again. Now, the workspace contains the repository, node_modules, and the build directory.
jobs:
deploy_qa:
docker:
- image: cimg/node:18.14.0
working_directory: .
steps:
- attach_workspace:
at: .
- run:
name: List contents of the build folder
command: ls -al build
- run:
name: Deploy to S3
command: aws s3 cp ./build s3://my-s3-bucket-url/ --recursiveUnderstanding the Result
When you list the contents of the root directory in the deploy job, you might expect to see only the build directory and the artifacts nested within the build directory. However, you will actually see the entire repository, node_modules, and the build directory. This is because each persist_to_workspace step adds to the workspace, and the workspace compounds the data across jobs.
Key Points to Remember
- Workspaces Accumulate Data: Each
persist_to_workspacestep adds to the existing data in the workspace. It does not replace it. - Explicit Management: Be explicit about what you persist and attach to avoid unnecessary data transfer.
- Verify and Debug: Use debugging steps, such as listing directory contents, to verify what is being persisted and attached.
Example: Explicitly Managing Workspace Contents
If you want to ensure only specific directories are present in the deploy job, you can use specific paths and directory management commands:
jobs:
deploy_qa:
docker:
- image: cimg/node:18.14.0
working_directory: ~/project
steps:
- attach_workspace:
at: /home/circleci/workspace
- run:
name: Copy build folder to project root
command: cp -r /home/circleci/workspace/build /home/circleci/project/
- run:
name: List contents of the build folder
command: ls -al /home/circleci/project/build
- run:
name: Deploy to S3
command: aws s3 cp ./build s3://my-s3-bucket-url/ --recursiveAlternative Method: Using save_cache
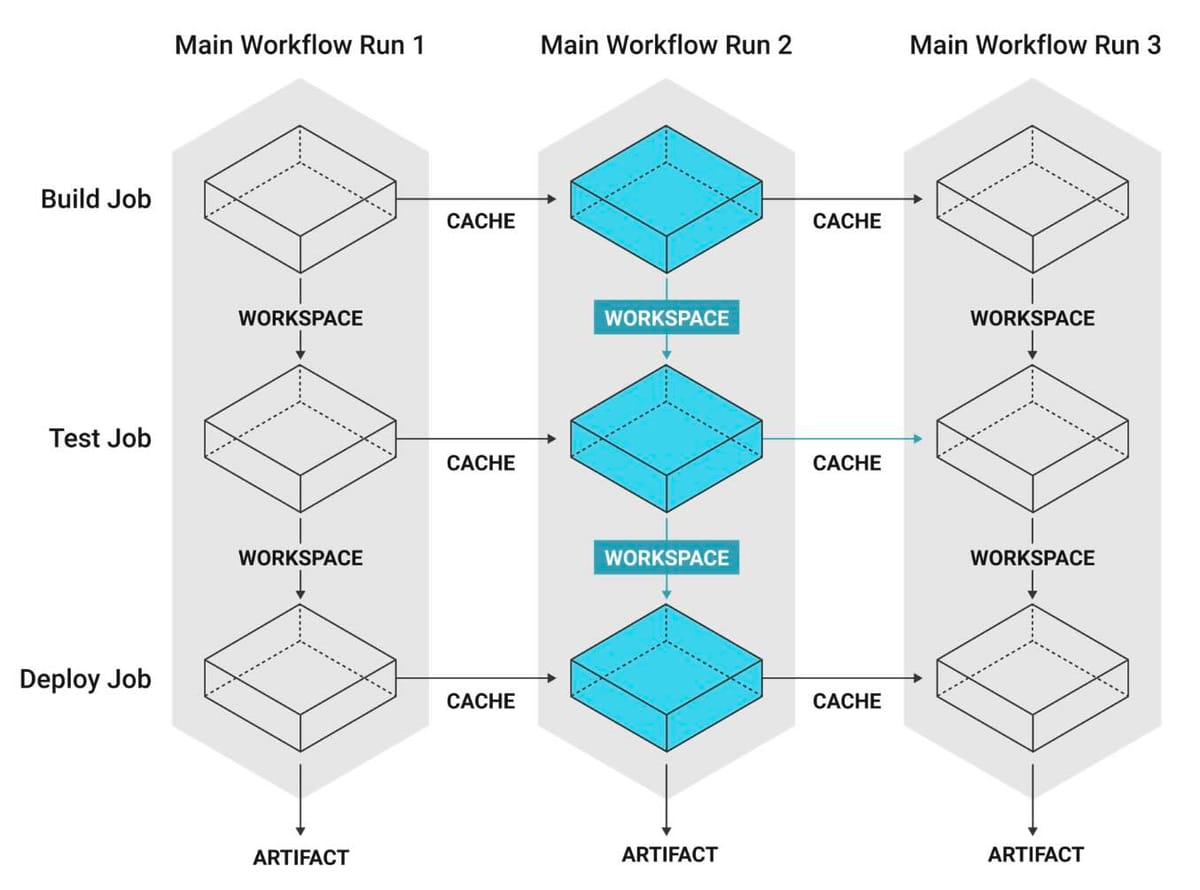
Before I realized that the workspace was compounding the files it received, I had reached out to my Principal Engineer for help. However, I managed to figure out the issue on my own before he replied, so I asked him to ignore my request for help. When I shared my findings, he congratulated me and mentioned that he wasn’t familiar with this method of sharing files across jobs. Instead, he introduced me to an alternative method he often uses: save_cache. This approach not only persists data between jobs but can also carry over data across different workflow runs. Here’s how you can use caching as an alternative:
jobs:
checkout_and_install_deps:
docker:
- image: cimg/node:18.14.0
working_directory: ~/project
steps:
- checkout
- run:
name: Install dependencies
command: npm install
- save_cache:
key: v1-dependencies-{{ checksum "package-lock.json" }}
paths:
- node_modules
build:
docker:
- image: cimg/node:18.14.0
working_directory: ~/project
steps:
- checkout
- restore_cache:
key: v1-dependencies-{{ checksum "package-lock.json" }}
- run:
name: Build project
command: npm run build
- save_cache:
key: v1-build-{{ checksum "package-lock.json" }}
paths:
- build
deploy_qa:
docker:
- image: cimg/node:18.14.0
working_directory: ~/project
steps:
- checkout
- restore_cache:
key: v1-build-{{ checksum "package-lock.json" }}
- run:
name: List contents of the build folder
command: ls -al build
- run:
name: Deploy to S3
command: aws s3 cp ./build s3://my-s3-bucket-url/ --recursiveOfficial CircleCI Documentation
For more detailed information on these methods, refer to the official CircleCI documentation:
Conclusion
Understanding how CircleCI workspaces compound data is crucial for managing your CI/CD pipeline effectively. By being explicit about what you persist and attach, and by verifying the contents at each step, you can avoid unexpected results and ensure your pipeline runs smoothly. Additionally, exploring other methods like caching can provide alternative solutions that might better fit your workflow needs.
If you’ve ever been puzzled by seeing more files than expected in your workspace, then I hope this guide helps you to understand the compounding nature of CircleCI workspaces. Thank you for reading and Happy Hacking!
Comments ()